Detecting Data Duplication at Scale
Written by Hitesh Garg
January 29, 2025
The Problem
Data is one of Apollo’s most sought-after resources, and a driver of escalations and churn is outdated or duplicate data. Customer Success (CS) and Research teams frequently flagged that Apollo was duplicating their data during prospecting and account-saving workflows - with varying degrees of severity.
💡Before we dive into the problem, we should take a moment to understand three core concepts :
Contacts,AccountsandOrganizationsIn Apollo’s system, a person named John Doe from New York working at Microsoft represents a Contact (John Doe) associated with an Account (Microsoft), which mirrors Apollo's core Organization (Microsoft) model.
Accounts can have attributes like name, domain, and organization_id.
When multiple Accounts exist with the same set of matching attributes, they are classified as duplicates—which is bad and useless data. This can disrupt our customers' critical workflows, leading to inefficiencies and frustration. And consequently wasted credits.
Certain escalations confirmed this reality—duplicate records were indeed being discovered. However, we haven’t done a comprehensive root cause analysis (RCA) recently to understand the volume and severity of the problem. But now the time had come! Given the scale of the issue and its impact on customer experience, this was a critical P0 initiative.
🔍 Root Cause Analysis (RCA)
We started with case-by-case investigations and identified 2 broad “categories” of data duplication:
- Apollo-specific workflows.
- Non-Apollo workflows (For eg, connecting and pulling accounts from a customer’s CRM like HubSpot or Salesforce).
Causes
We narrowed down the reasons to 4 primary ones
- Organization ID Oscillation
- Organization ID is a critical identifier for detecting duplicate accounts. However, Apollo intermittently switched Organization IDs due to internal data inconsistencies.
- This issue stemmed from an edge case where incomplete payloads were passed to the account matching algorithm, leading to incorrect reassignments.
- As a result, accounts oscillated between different Organization IDs, significantly contributing to duplication.
- Race Conditions
- Certain Apollo workflows encountered race conditions, leading to inconsistencies in the account-matching algorithm.
- These workflows attempted to create accounts using the same attributes, but since they executed within fractions of a second, duplicate entries were created before proper de-duplication checks could complete.
- The solution is to implement Redis-based distributed locking, preventing concurrent processes from creating duplicate accounts simultaneously.
- Issues with Account Domain Fetcher
- When an account is created in Apollo using only a name (e.g., “Slimy Corp”), Apollo’s Data Network attempts to enrich it with additional information, such as domain and Organization ID.
- The Account Domain Fetcher uses a complex algorithm to determine the correct domain and Organization ID.
- However, due to competing workflows operating on the same account simultaneously, the Organization ID was being incorrectly updated, leading to duplicate accounts.
- CRM Unmatching Bug
- When Apollo syncs records from a customer’s CRM, it attempts to match them with existing accounts that aren’t linked to other CRM records.
- However, a flaw in the account matching algorithm caused an unintended behavior:
- The algorithm initially linked the incoming CRM account to an existing CRM-linked account.
- But in subsequent steps, it unmatched that account and did not check for the next eligible account, resulting in duplicate accounts being created instead of maintaining a correct link.
Solution
- Identifying Duplicate Accounts
- We selected key account properties (e.g., name, domain, organization ID) and identified accounts sharing identical properties. This step was a simple one but gave us a starting point.
- Tracing Duplication Sources
- The bigger challenge was pinpointing how and when these duplicates were created and what is the biggest contributing source
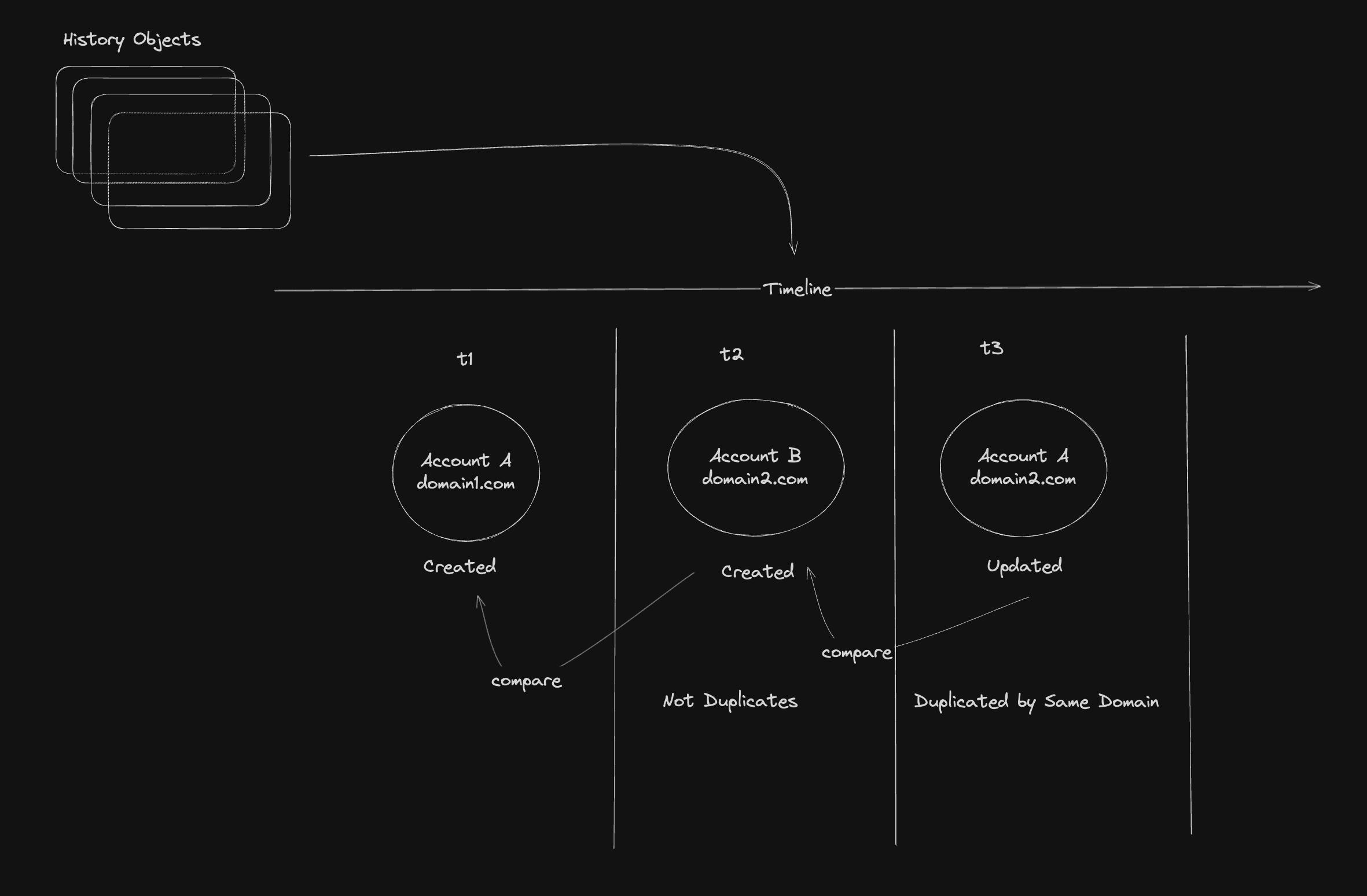
- Using Apollo’s audit logs, we traced the timeline of each duplicate account creation or updation. By piecing together the account’s lifecycle, we identified trigger points and timestamps where duplication occurred.
This was the fundamental 2-step process for detecting sources of duplication. Diagrammatically speaking, it looks something like this
📈 Scaling the RCA Itself!
Fixing the gaps in the workflows with one-off brought some progress, but the issues persisted because new workflows—plays, prospecting, CRM syncs, and many more —contributed to duplication. With the current approach of handling the escalations as one-offs, keeping track of these and finding long-term solutions became unsustainable.
This meant our investigation process also needed to scale.
To operationalize and scale it, we built a tool capable of “detecting-analyzing-visualizing” duplicate Accounts.
🛠️ Duplicate Detection Tool
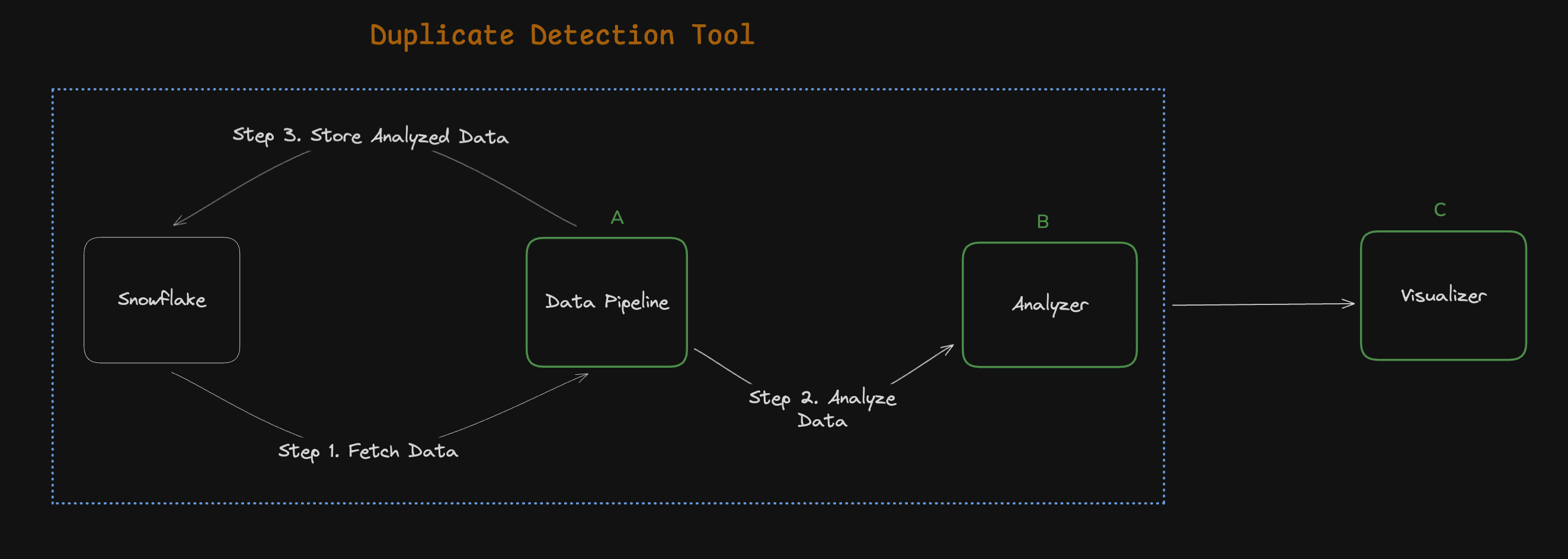
A. Data Pipeline
- To analyze accounts at scale given that Apollo has billions of accounts a proper data processing pipeline was needed. And finding duplicates is akin to finding a needle in a massive haystack.
- A pipeline using Spark was set up to identify duplicate accounts. This pipeline stores data in Snowflake, as the analysis is intensive—each account requires examining related attributes and querying data models like user history.
- Detecting duplicate accounts becomes more challenging when dealing with transitive relationships on a large dataset. Consider the following scenario:
- Account A matches with Account B based on a shared domain.
- Account B matches with Account C based on a name similarity.
- Although there is no direct match between Account A and Account C, they should still be considered duplicates due to their transitive relationship.
- In other words, identifying duplicate accounts is equivalent to finding connected components in a graph, where:
- Nodes represent accounts.
- Edges represent matching criteria (such as shared domains, names, etc.).
- Given N accounts, the challenge is to efficiently group connected accounts into clusters. This problem can be solved using an efficient Union-Find (Disjoint Set Union - DSU).
B. Analyzer
- A key component in our solution is the Duplicate Analyzer, which deeply examines account audit logs. This tool helps identify the exact point in time and the specific workflow that led to duplication.
- To standardize duplicate detection, we developed a Python library that computes duplicate accounts efficiently when used in snowflake-based data pipelines. This library also integrates with Apollo’s customer app to show duplicate reasons on UI to them.
- Also, instead of just tagging known bugs, we focused on detecting behaviors in the system. Whenever any workflow didn’t behave as expected, we flagged the scenario and emitted metadata to help debug the situation. This approach allowed us to prioritize workflows based on the frequency of unexpected behaviors, ensuring that we tackled the most critical issues first.
C. Visualizer
- The duplicates data feeds into a health dashboard, offering insights into data quality and duplication trends.
- An API provides this information to end users, displaying duplicate accounts on their ID pages along with explanations of the duplications and options to merge them.
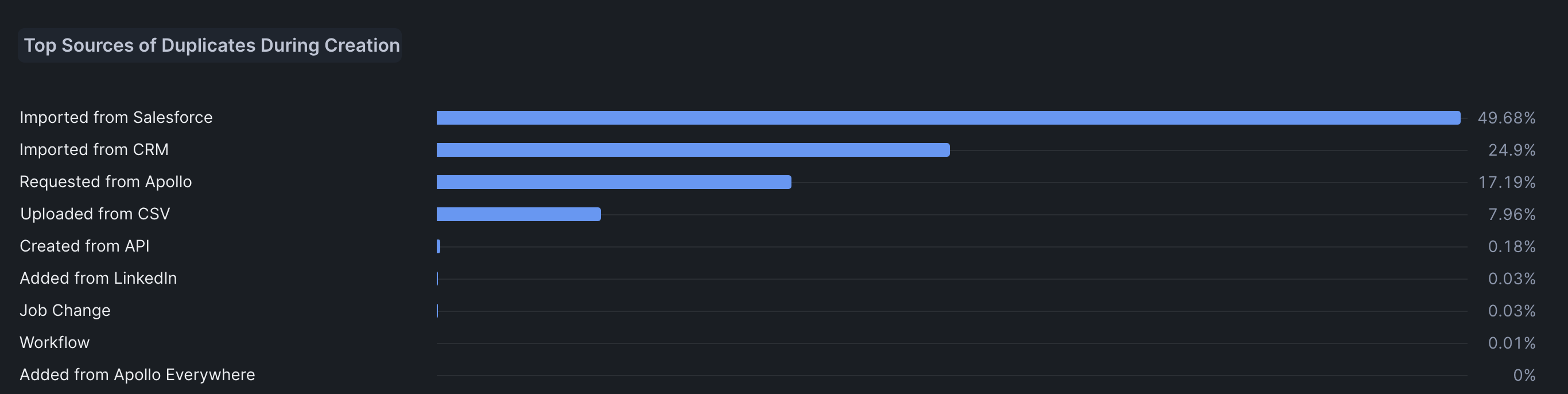
Impact
The key wins of this initiative can be summarized as follows:
- We successfully identified and quantified the top workflows contributing to duplicate accounts in Apollo. Our analysis revealed that data ingested from customer CRMs was responsible for nearly 90% of duplicate accounts. Additionally, a single customer had duplicates accounting for 55% of their total accounts.
- An admin UI, built on top of the Analyzer Tool, is now accessible to Apollo’s Customer Success (CS) team. This reduces the dependency on the engineering team for identifying duplication issues, thereby speeding up resolution times for customer escalations.
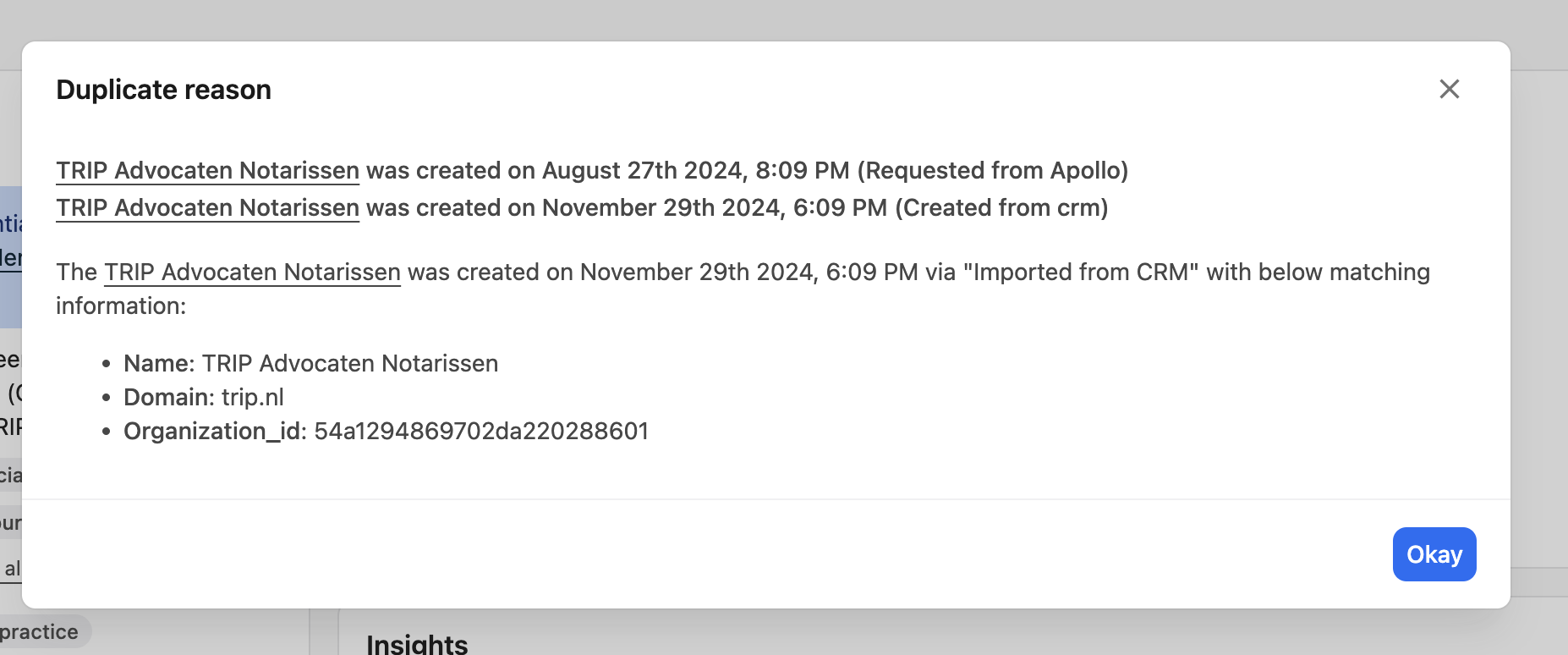
- The manual investigation of duplicate accounts was a complex and time-consuming process, requiring significant engineering on-call bandwidth. With the new system in place, we expect a considerable reduction in manual intervention, allowing engineers to focus on higher-impact initiatives.
🔮 We are hiring…
With scalable processes in place, identifying and resolving duplication issues has become more efficient, saving time and improving data quality.
Our data deduplication tool has set the stage for a healthier database and happier customers. And many more such complex problems are being solved by our engineers for our customers.
Are you ready to be part of this journey? Come join us at Apollo.io, and let’s build something extraordinary together. Click here to apply now!